
{kind=link}
Resumen
Este proyecto regional desarrolla un simulador de ecosistemas donde agentes con distintos roles aprenden a sobrevivir, competir y adaptarse dentro de un entorno compartido. La propuesta combina aprendizaje por refuerzo profundo con Modelos Grandes de Lenguaje (LLM) para estudiar cómo emergen estrategias de búsqueda de alimento, evasión, depredación y toma de decisiones en escenarios ecológicos dinámicos.
La primera fase se concentra en un entorno 2D con múltiples agentes, recursos y reglas de interacción. Sobre esa base se entrena a herbívoros y depredadores para observar si aprenden comportamientos funcionales, medir su desempeño a lo largo de miles de episodios y documentar qué patrones aparecen de manera espontánea a partir de la experiencia.
Además de su valor como plataforma experimental en inteligencia artificial, el simulador busca convertirse en una herramienta útil para explorar dinámicas ecológicas, comunicación entre agentes y futuras integraciones con entornos tridimensionales.
Arquitectura de trabajo
1. Entorno
Se construye un ecosistema simplificado con agentes, alimento, agua y reglas de interacción para permitir experimentación controlada.
2. Aprendizaje
Los agentes entrenan estrategias de supervivencia mediante aprendizaje por refuerzo profundo, ajustando su comportamiento a partir de recompensas.
3. Interpretación
Los LLM aportan una capa futura de razonamiento, explicación y comunicación natural para describir por qué los agentes actúan como lo hacen.
4. Escalamiento
La hoja de ruta contempla explorar una versión 3D con Minecraft y MineRL para evaluar interacciones más complejas.
Comportamientos emergentes observados
Búsqueda de alimento
En una de las escenas compartidas se observa a un chancho de monte en el instante previo a comer, mostrando que el agente ya reconoce el recurso y ejecuta una acción orientada a su supervivencia.

01-godot-comida-caza.jpg
Evasión de depredadores
Otra visualización muestra cómo los chanchos empiezan a modificar su movimiento para alejarse de los depredadores, señal de que el entrenamiento está generando respuestas adaptativas más allá del movimiento aleatorio.

02-godot-evasion-depredadores.jpg
Aprendizaje simultáneo
En una tercera escena se combinan ambos procesos: mientras unos agentes mejoran su capacidad para encontrar comida, otros aprenden a evitar amenazas dentro del mismo entorno compartido.

03-godot-comportamientos-juntos.jpg
Métricas y hallazgos preliminares
Progreso sostenido
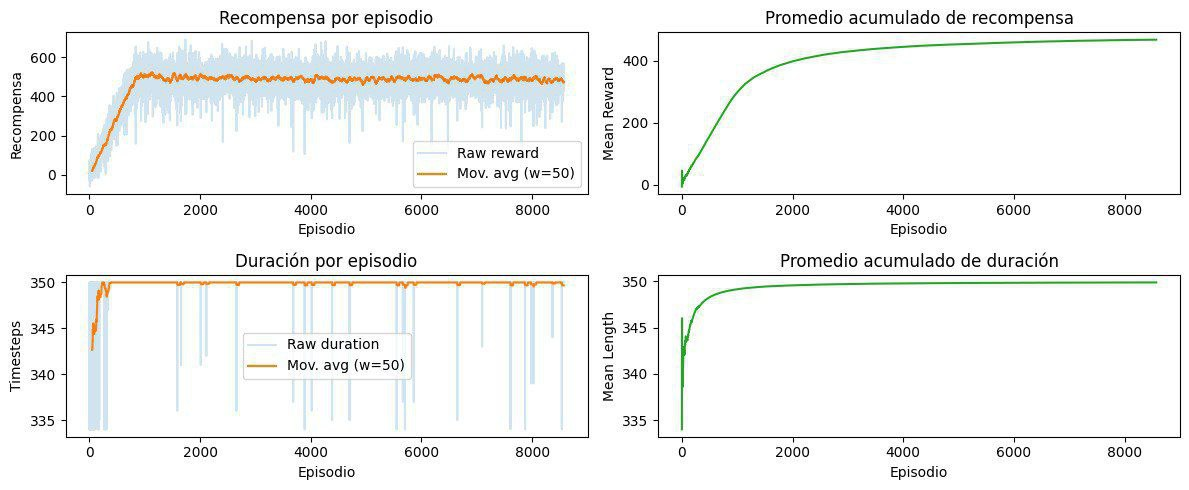
El resumen de entrenamiento a lo largo de 2000 episodios evidencia una mejora clara en el rendimiento de los agentes, indicando que el sistema sí está aprendiendo políticas más útiles con el tiempo.
04-progreso-2000-episodios.jpg
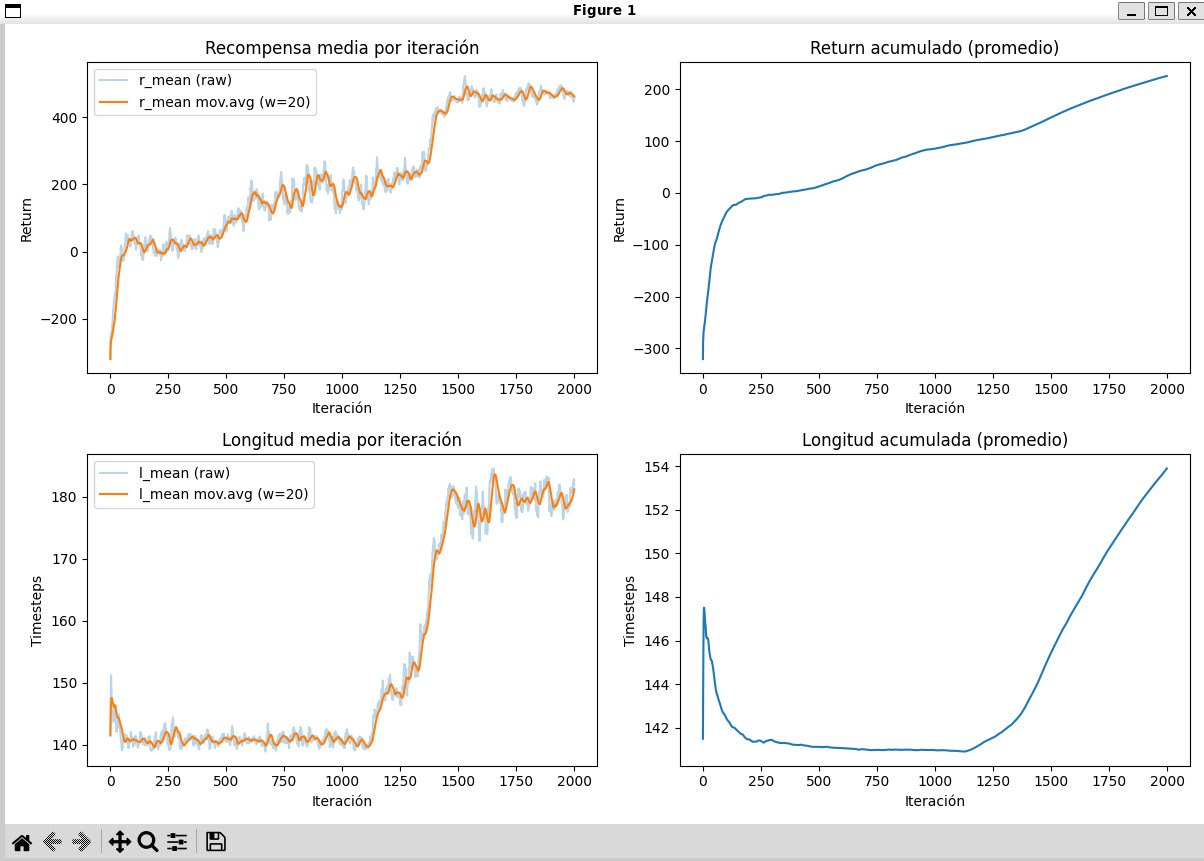
Recompensas diferenciadas por rol
La comparación de retornos muestra trayectorias distintas entre herbívoros y depredadores. Las curvas sugieren que ambos grupos descubren estrategias diferentes para maximizar sus recompensas dentro del ecosistema.
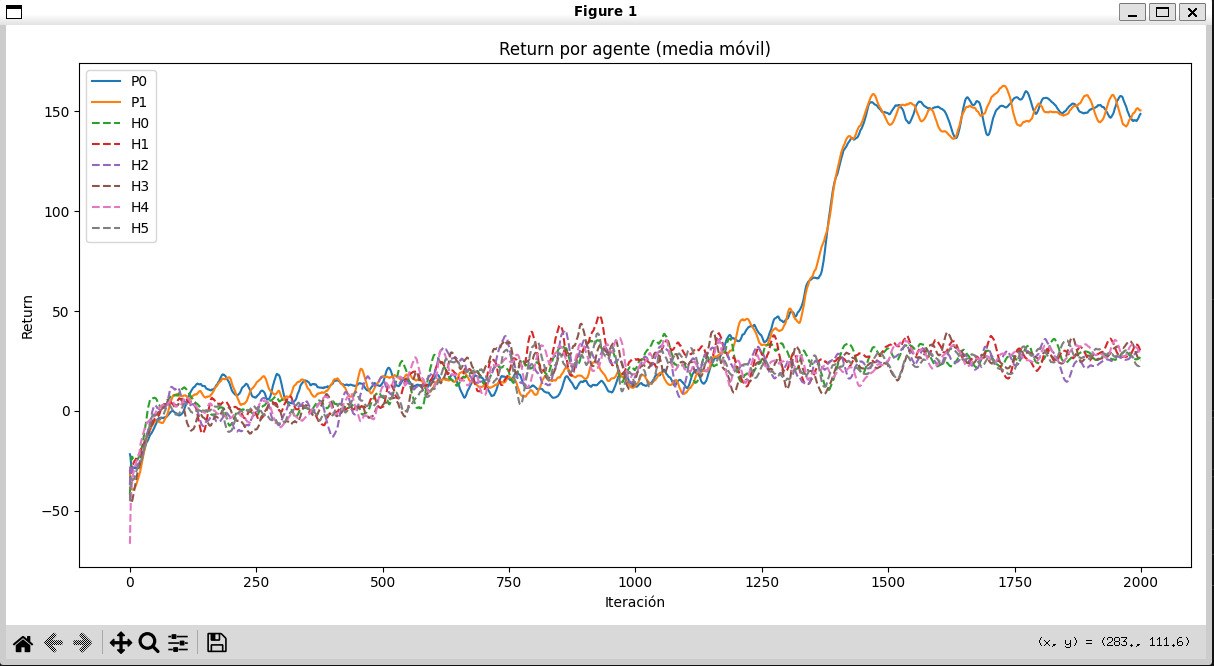
05-retorno-por-agente.jpg
Límite actual del entorno
La supervivencia por rol se mantiene lejos de los 350 pasos completos en todos los episodios, lo que deja claro que el entorno sigue siendo exigente y que aún hay espacio para mejorar las políticas aprendidas.
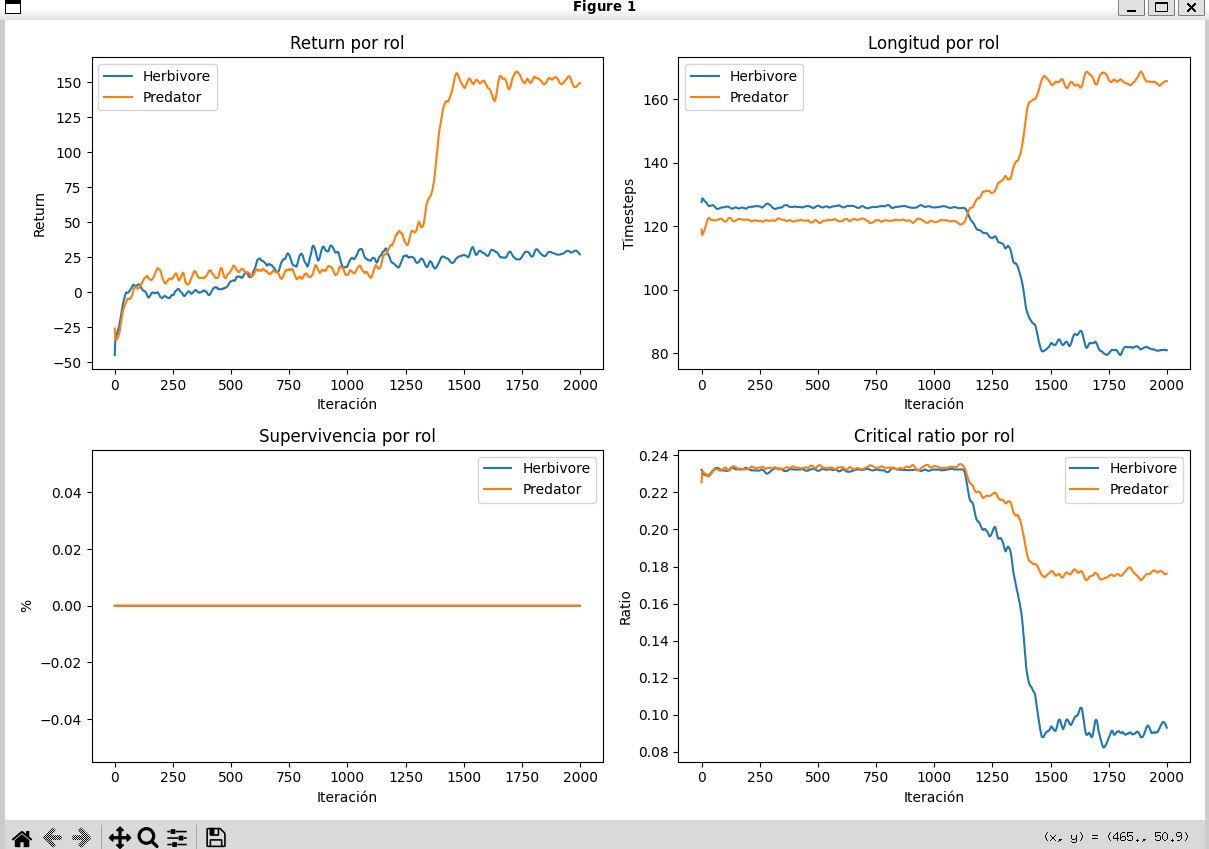
06-supervivencia-por-rol.jpg
Mayor resistencia con el entrenamiento
La longitud de los episodios por agente permite observar cuánto tiempo logra sostenerse cada individuo antes de morir. Esta métrica ayuda a distinguir aprendizaje real de mejoras aparentes solo en recompensa.
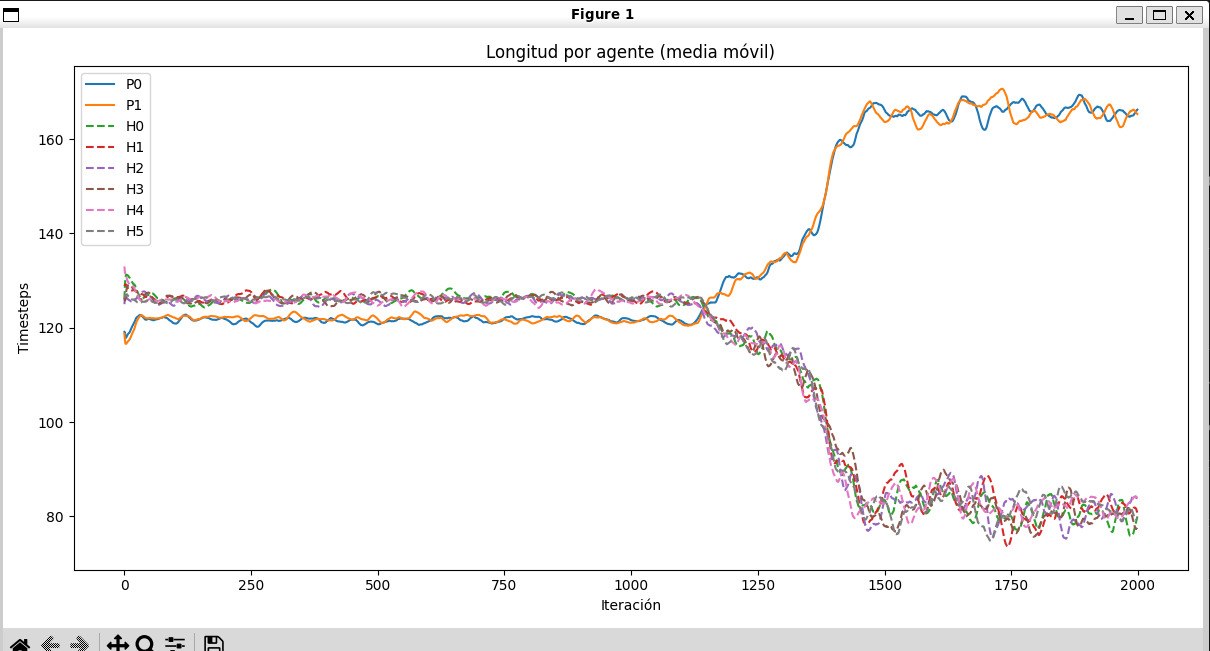
07-longitud-por-agente.jpg
Cambio de presión ecológica
Los herbívoros comienzan muriendo principalmente por hambre o sed, pero luego aumenta la mortalidad por depredación. En los depredadores ocurre lo contrario: la falta de agua termina siendo un problema más importante que la falta de alimento.
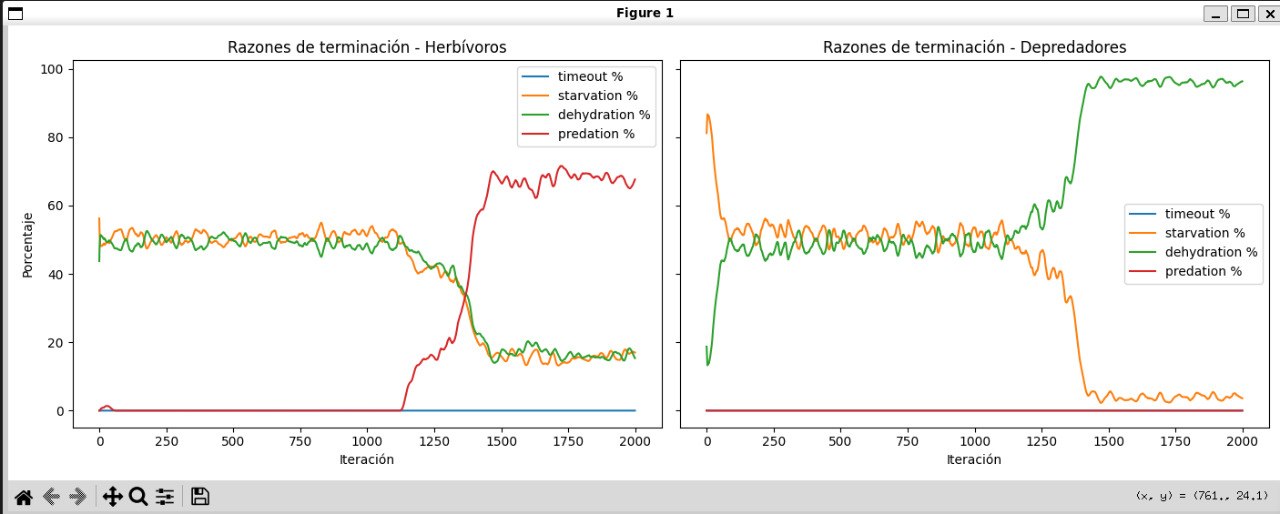
08-causas-de-muerte.jpg
Ventaja alimentaria de depredadores
El promedio de recursos obtenidos por rol sugiere que los depredadores consiguen alimento con mayor facilidad, aunque casi no consumen agua, lo cual coincide con sus patrones posteriores de mortalidad.
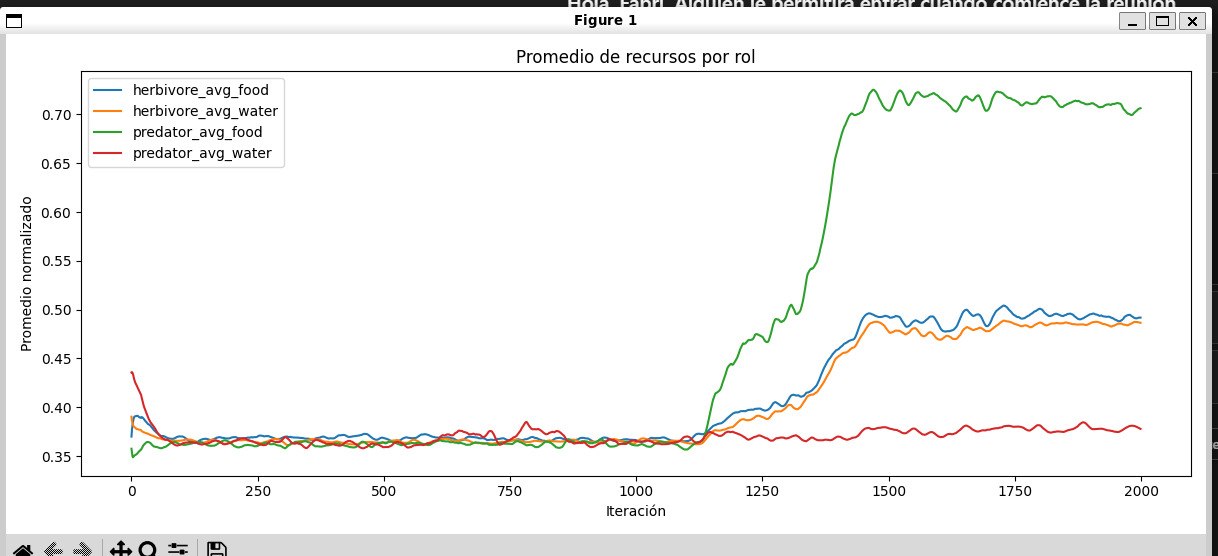
09-recursos-por-rol.jpg
Umbral de activación táctica
A partir de aproximadamente el episodio 1100 aumenta la cantidad de ataques realizados por los depredadores. Este cambio es consistente con la aparición de conductas más activas de caza en las demás métricas.
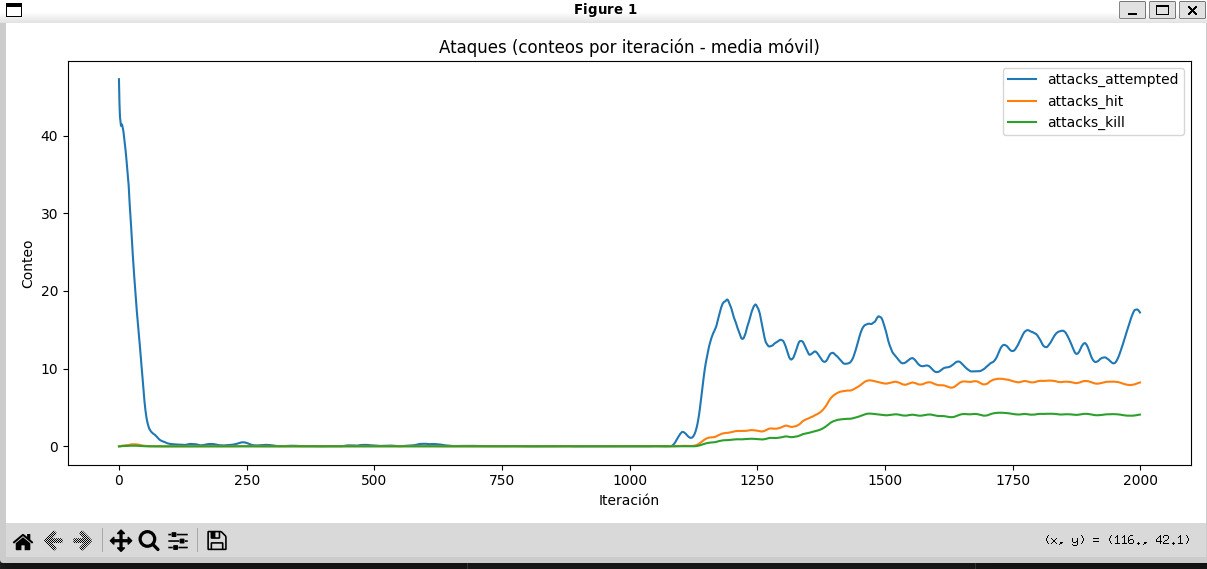
10-ataques-por-episodio.jpg
Siguiente etapa
La proyección del proyecto incluye enriquecer el entorno, refinar las recompensas, incorporar explicaciones generadas por LLM para interpretar decisiones de los agentes y evaluar una expansión a escenarios 3D con Minecraft y MineRL. Esa transición permitiría estudiar interacciones más complejas, navegación espacial avanzada y nuevas formas de cooperación o competencia.